Cassandra VS Dynamo 教程详解
编辑: admin 2017-04-08
-
Cassandra VS Dynamo 教程详解
-
4
1. Cassandra 简介
大家好,我们今天的主题是Cassandra.
Cassandra是一个open source, distributed, decentralized, elastically scalable, highly available, fault-tolerant, tuneably consistent, column-oriented的数据库。
大家可能会问,Cassandra与DynamoDB有什么关系呢?为什么要放在Dynamo扩展篇里面讲呢?
实际上这俩大名鼎鼎的nosql数据库体系的确有着千丝万缕的关系。有人说,Cassandra is the daughter of Amazon DynamoDb and Google Bigtable. Cassandra的data model 衍生自Bigtable,而它的distributed design则参考了Dynamo,他们都采用了一种叫做distributed hash table(DHT)的P2P结构,与传统的基于Sharding的数据库集群相比,Cassandra可以几乎无缝地加入或删除节点,非常适于对于节点规模变化比较快的应用场景。
我希望通过将Cassandra与DynamoDb对比,给大家带来一些思考。DynamoDb的设计是否完美无缺?实际应用中,它可能面对哪些问题呢?
Cassandra项目一开始是为了Facebook inbox search服务的,旨在提供一个scaled storage system以解决快速增长的数据问题。由Avinash Lakshman主持编写,这哥以前在Amazon工作,是DynamoDb的作者之一,所以我们不难理解为什么Cassandra借用了那么多Dynamo的特性了,一脉相承嘛!
好,下面来详细介绍Cassandra。
2. Cassandra 数据库
2.1 Data Model 数据库模型
首先是data model,这是Cassandra与Dynamo最大的不同点所在。Dynamo使用的是key-value pair store, 而Cassandra使用的是与Google Bigtable相似的column oriented key-value store. 我们先来看两幅图:
- DynamoDb data model 示例
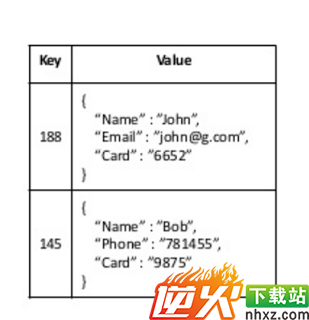
- Cassandra data model 示例
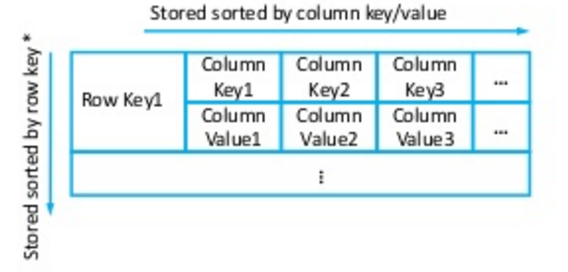
最明显的区别就是Cassandra的每一行都是semi-structured的,由多个column组成,但是要注意这里no relations,relation db的columns是预先定义好且不能改变的,Cassandra则可以随意增减column。
有了column的支持,数据库的操作也就有所不同了,Dynamo只能对整个row进行操作,而Cassandra却可以精确到row中的某一column! 看一下他们的api,非常明显
Dynamo api: get(key), put(key, context, object)
Cassandra api: get(table, key, columnName),insert(table, key, rowMutation),delete(table, key, columnName)
总结一下,Cassandra的data model定义如下:
Map
2.2 Distributed Design
接下来看一下cassandra的distributed design
(1)分区
分布式存储系统必然要把数据partition/distribute到不同的节点上存储,大家从昨天DynamoDb的课上学到的一致性哈希consistent hashing也被用作cassandra的partition algorithm,简单复习一下,这是一个hash ranges组成的环式结构,没有master,只有一种类型的节点,每一个节点负责它和上一个节点之间的数据,借用一下昨天孙同学的图。
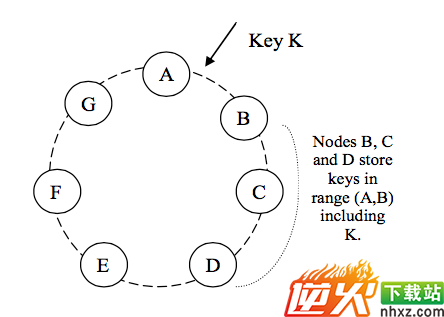
DynamoDb为了实现load balance,引入了virtual node的概念,期望其在整个集群中分散负载的作用,即一个物理节点承担多个逻辑节点的任务,这样当一个新物理节点加入时,期待所有其他物理节点向其迁移数据。当一个物理节点故障时,同样期待将其数据由所有其他物理节点暂管。原本consisten hashing中希望节点只会影响与它相邻的节点,然而DynamoDb为了balancing和对节点异构能力的支持,对设计原则造成了打破。
在cassandra的早期实现中,是没有virtual nodes的,后来的版本中虽然加入了virtual nodes的实现,但是提出了一些担心,假设一个物理节点非常大(TB),在向其他节点迁移的时候会带来很大的DISK I/O, NETWORK I/O, CPU开销,这种负荷会拖垮整个cluster,一些采用cassandra的网站如Reddit, Digg的事故报告中都提到了这个问题。必须采用合适的stream throttling方法进行控制。
再者,Virtual Nodes的维护是一个大问题,早期cassandra是靠人工配置来维护的。试想每个节点有几百个Virtual Nodes,要保证其不能相邻,否则散列会不均匀,balancing无法实现。这种方法如果做成动态的,节点在ring上的移动将很频繁,而造成控制混乱。如果靠手动维护,维护工作又很繁重。
(2)数据一致性
Dynamo和Cassandra支持用户总是可写,而解决一致性冲突留给了读操作,从而获得了很好的性能增益。回顾一下N W R模型。N代表N个备份,W代表要写入至少W份才认为成功,R表示至少读取R个备份,要求W+R > N,也就是 R > N-W。Cassandra希望实现可调的一致性(tunable consistency),即通过调整R W的值,实现available和consistency之间的转换。
给W配置一个小值R配置一个大值则"writes never fail"(high availablility);给R配置一个小值W配置一个大值则"block for all replicas to be readable"(strong consistency)
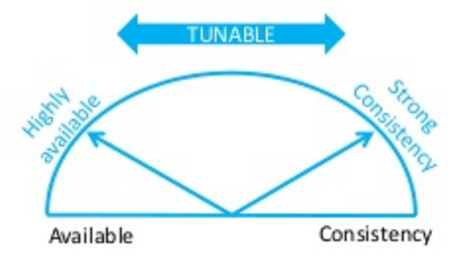
看上去非常灵活!那我们来思考一下可能会有什么不足之处呢?
a. 由于读操作时做一致性检查,对于write多read少的应用数据,read repair几乎不能保证数据的一致性。结果是数据长期不一致,甚至永远不一致。因为很多数据可能很久或者永远也不会被读到。
【Question】什么是Read Repair呢?
就是写的时候我们不要求strong consistency,read的时候才进行一致性的检查与修复。比如NWR中N=3, W=1, 在写的时候,只需要一份replica被修改就成功了,读的时候如果我们只读一份replica,那么很有可能读到的被修改的这份.所以要实现high availability我们要在w=1的同时设置R=3才能保证所有3份data都被读到,这时候再解决inconsistency的问题,就叫做read repair。
b. DynamoDb离线检查采用的Merkle Tree算法对于静态数据是比较有效的,但由于每次比较必须对现有数据重建Merkle Tree,如果数据总是不一致重建Merkle Tree需花太多系统资源和时间。Dynamo的数据模型是简单的key-value,而且每个key-value都很小。Merkle Tree用于这种数据模型也许是适用的。但对于Cassandra的数据模型Key-Columns,因为操作时的粒度是Column,每个列都要有自己的Merkle树,而且出现同一个Key的不同Column不一致的情况更加普遍,这种同步策略是否适应有待考验
再简单提一下,大家可能还记得昨天的课上有提到在merge多版本数据时DynamoDb使用了Vector Clock的数据结构,即一个<节点编号,计数器>对的列表,这个结构作为context,保存在节点的metadata中。
在Cassandra中,data model不同,熟悉Bigtable的同学可能会知道三元组
(3)故障检测
当一台机器挂掉之后,怎么通知所有的结点这个信息呢?Dynamo和Cassandra系统去中心化,没有一个结点是管理员这样的角色,通知大家一起更新。在这种环境下,各个结点之间用peer-to-peer通信方式,基于gossip protocol。简单来说,就是模拟人类社会中流言传播的方式。每个节点随机地把消息发给它的邻居,接到消息的节点,如果之前没收到这个消息,则会继续随机地转发给它的邻居,否则不转发。这样,失败的结点或者成员信息的变化会像流言一样迅速到达Dynamo的所有结点。
“Hinted Handoff”是Dynamo和Cassandra的临时性故障修复方式,简单的说就是让其他节点暂时存储某个掉线机器的data,等该机器上线后再把data“还给”该机器,并从暂时存储的机器中删除备份。为了避免整个机房掉线的问题,配置”Preference List”使数据就尽量写到不同数据中心的节点上。但如果数据中心之间相距很远,如一个机房在北美洲,一个在亚洲,则需要担心一下low latency的问题。
3. Use Case: Ebay
3.1 Infrastructure工作模式
最后我们来简单看一下Cassandra的实际应用案例。以ebay为例,首先是一些statistics帮助我们对其data scale有个初步的了解:

ebay的data infra是relational db和nosql混合,现在主要还是relational db,不过他们正在努力迁徙到nosql上,主要是因为有一些use case关系数据库不合适,比如sparse data,big data,schema optional, real time analytics,而且在scalibility上nosql更灵活。
一张图展示其Cassandra deployment:
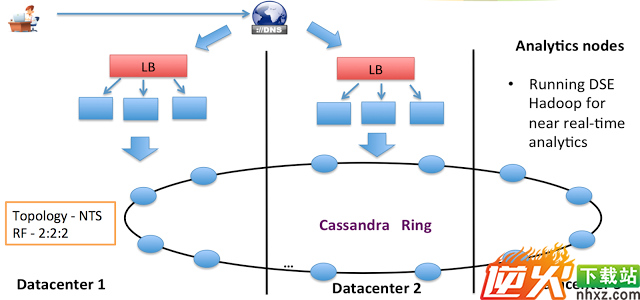
三个数据中心构成了一个大型consistent hash ring,dns将用户的请求分配给最近的load balancer,再由其分发给其下的application server,application server与最近的data center通信。我们看到有一个data center专门留给了real time analytics,这一块主要是各种log的记录以及分析(performance monitoring,fraud detect...)
3.2 Use case: Like 实例演练
再来简单看一个use case,ebay商品界面的like功能就是由cassandra负责的。
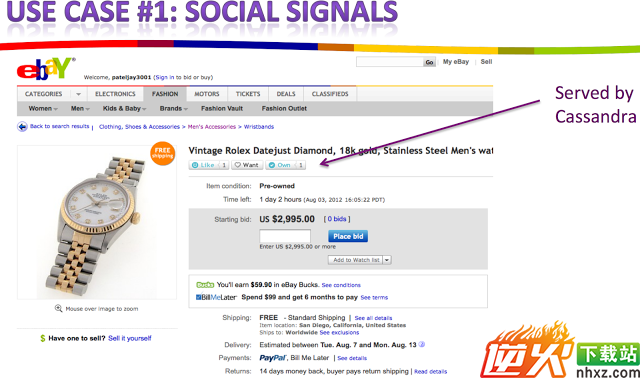
- Data Model 数据模型
Data Model部分,可以看出有多个表和这个功能有关:

可以看到每个表都是典型的colum-oriented key-value store,userid或itemid作为row key, likeCount是其中一个column。用户的一个更改将会影响四张表,并且同时可能有很多用户并发修改,实际上中间有很多非常麻烦的问题。
- Duplication Issue 问题症结
比如我们很多人都遇见过的情况,由于网速的关系,会一下子连按几次like按钮。like, unlike, like。UserLike表应该发生的变化是,插入item,删除item,插入item。。因为Cassandra always allow write,删除操作还没同步到某个节点的UserLike表中,新的记录就插入了,这时候读UserLike表,可能会展示出多个duplicate的item。
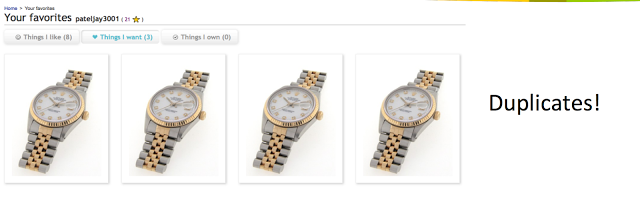
ebay的架构师提了好几个解决方案,都不够完美,最后的办法就是我们提到的repair read,但是这样又会造成read时一定的性能损失。
4. Summary 记录日志总结
今天通过比较Cassandra和DynamoDb,我们了解了设计一个分布式存储系统是多么复杂的一件事。Dynamo的Read Rapir, Hinted Handoff、Merkle Tree、Virtual Nodes,Clock Vector等技术,其实都是为了修补其架构和设计原则缺陷而采用的方法。灵活性必然带来复杂性,不论是在开发时还是运维时。在实际运用该架构时,总是需要各种trade off,根据自身硬件以及use case的情况,调整strategy。
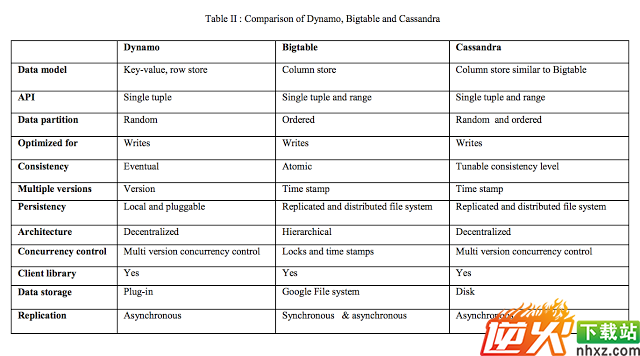
最后送上一张Dynamo, Bigtable和Cassandra的总结表,谢谢大家~